Towards Surveillance Video-and-Language Understanding: New Dataset, Baselines, and Challenges(CVPR 2024)


Abstract
Surveillance videos are an essential component of daily life with various critical applications, particularly in public security. However, current surveillance video tasks mainly focus on classifying and localizing anomalous events. Existing methods are limited to detecting and classifying the predefined events with unsatisfactory semantic understanding, although they have obtained considerable performance. To address this issue, we propose a new research direction of surveillance video-and-language understanding, and construct the first multimodal surveillance video dataset. We manually annotate the real-world surveillance dataset UCF-Crime with fine-grained event content and timing. Our newly annotated dataset, UCA UCF-Crime Annotation), contains 23,542 sentences, with an average length of 20 words, and its annotated videos are as long as 110.7 hours. Furthermore, we benchmark SOTA models for four multimodal tasks on this newly created dataset, which serve as new baselines for surveillance video-and-language understanding. Through our experiments, we find that mainstream models used in previously publicly available datasets perform poorly on surveillance video, which demonstrates the new challenges in surveillance video-and-language understanding. To validate the effectiveness of our UCA, we conducted experiments on multimodal anomaly detection. The results demonstrate that our multimodal surveillance learning can improve the performance of conventional anomaly detection tasks. All the experiments highlight the necessity of constructing this dataset to advance surveillance AI.
The following figure shows Annotation Examples in our UCA dataset.

Dataset Description
Comparative Analysis with Other Video Datasets
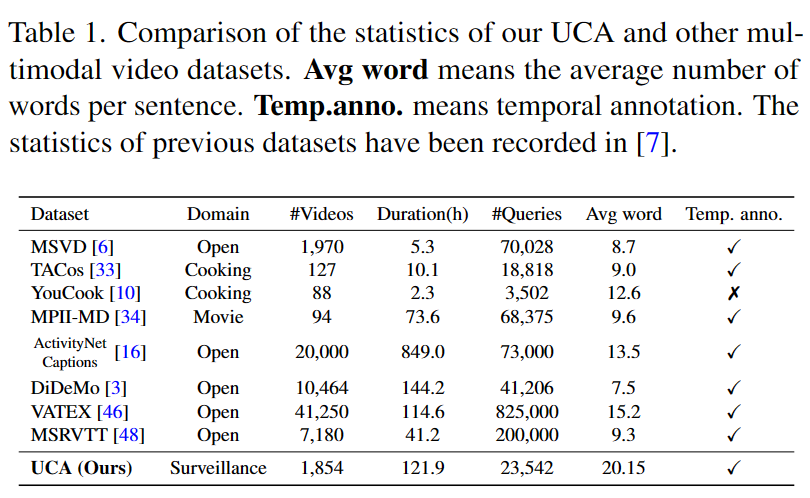
The following table provides a statistical comparison between the UCA dataset and other traditional video datasets in multimodal learning tasks. Our dataset is specifically designed for the surveillance domain, featuring the longest average word count per sentence.
Quality and Fairness Assurance
During the video collection process for UCA, we conducted a meticulous screening of the original UCF-Crime dataset to filter out videos of lower quality. This ensures the quality and fairness of our UCA dataset. The low-quality videos identified had issues like repetitions, severe obstructions, or excessively fast playback speeds, which impeded the clarity of manual annotations and the precision of event time localization.
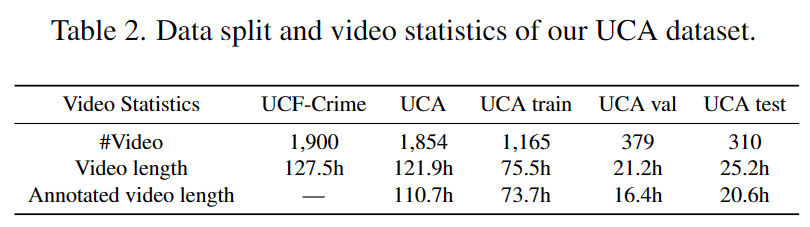
Consequently, we removed 46 videos from the original UCF-Crime dataset, resulting in a total of 1,854 videos for UCA. The data split in UCA is outlined in the table below.
Parts of Speech Distribution
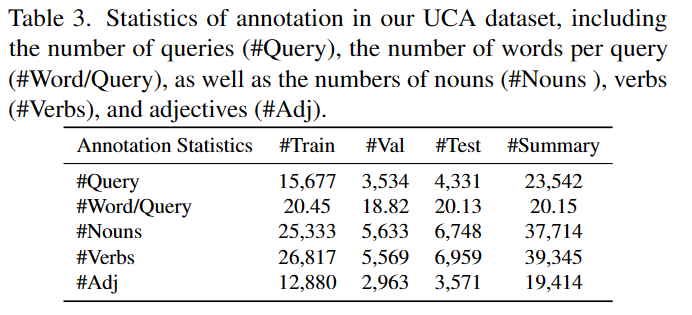
The table below displays the number of query descriptions for the events we labeled and the average number of words per query. The average word count in our annotations is approximately 20 words. The distribution of parts of speech (nouns, verbs, and adjectives) is approximately 2:2:1 in all sentences of the Train, Val, and Test splits.
Format Explanation
The UCA dataset is available in two formats: txt and json.
txt format:
VideoName StartTime EndTime ##Video event description
json format:
"VideoName": {
"duration": xx.xx,
"timestamps": [
[StartTime 1, EndTime 1],
[StartTime 2, EndTime 2]
],
"sentences": ["Video event description 1", "Video event description 2"]
}
Experimental Tasks
We conducted four types of experiments on our dataset:
- Temporal Sentence Grounding in Videos (TSGV): This task focuses on temporal activity localization in a video based on a language query.
- Video Captioning (VC): Understanding a video clip and describing it with language.
- Dense Video Captioning (DVC): Involves generating the temporal localization and captioning of dense events in an untrimmed video.
- Multimodal Anomaly Detection (MAD): Utilizes captions as a text feature source to enhance traditional anomaly detection in complex surveillance videos.
Visualizations
To better understand the dataset and the experimental outcomes, the following visualizations are included:
TSGV Visualization
Example by MMN.

VC Visualization
Example by SwinBert.

DVC Visualization
Example by PDVC.

MAD Captioning Results
Examples of different video captioning results.

Original UCF-Crime Dataset Reference
Our UCA dataset is built upon the foundational UCF-Crime dataset. For those interested in exploring the original data, the UCF-Crime dataset can be downloaded directly from this link: Download zip URL: www.crcv.ucf.edu/data1/chenchen/UCF_Crimes.zip
Additionally, further details about the UCF-Crime project are available on their official website: Visit here
If you wish to reference the UCF-Crime dataset in your work, please cite the following paper:
@inproceedings{sultani2018real,
title={Real-world anomaly detection in surveillance videos},
author={Sultani, Waqas and Chen, Chen and Shah, Mubarak},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={6479--6488},
year={2018}
}
Each annotation in our UCA dataset is associated with a corresponding video in the original UCF-Crime dataset. Users interested in this dataset can easily match the videos to the annotation information after downloading.
Usage and Contact
Our dataset is exclusively available for academic and research purposes. Please feel free to contact the original authors for inquiries, suggestions, or collaboration proposals.
Citation
@misc{yuan2023surveillance,
title={Towards Surveillance Video-and-Language Understanding: New Dataset, Baselines, and Challenges},
author={Tongtong Yuan and Xuange Zhang and Kun Liu and Bo Liu and Chen Chen and Jian Jin and Zhenzhen Jiao},
year={2023},
eprint={2309.13925},
archivePrefix={arXiv},
primaryClass={cs.CV}
}